Yiming Wang

Hi! I am Yiming, a senior researcher at Fondazione Bruno Kessler. I am enthusiastic on robotic perception, covering diverse topics related to 2D/3D scene representation, scene semantic understanding and embodied navigation/manipulation. My recent research focuses on leveraging multimodal foundation models for embodied perception and reasoning. I am a member of ELLIS.
I work and live in Trento, a beautiful mountain city in northern Italy, providing me with great balance between nature peace and research stress :P
News
| Jan 09, 2026 | 🎉 Congrats to Alessandro who FINALLY got his journal paper accepted by TPAMI! |
|---|---|
| Dec 22, 2025 | 🧑💻 I will serve as Area Chair for ECCV 2026! |
| Dec 12, 2025 | 🎉 Our paper TeGu on zero-shot temporal action localization is accepted to FG2026. Congrats to Benedetta! |
| Oct 19, 2025 | 🎉 Our paper CoIN was awarded as Outstanding paper in I-HFM workshop at ICCV 2025! |
| Sep 18, 2025 | 🎉 2/2 papers accepted to NeurIPS 2025! Congrats to Benedetta and Luca! |
Selected publications
-
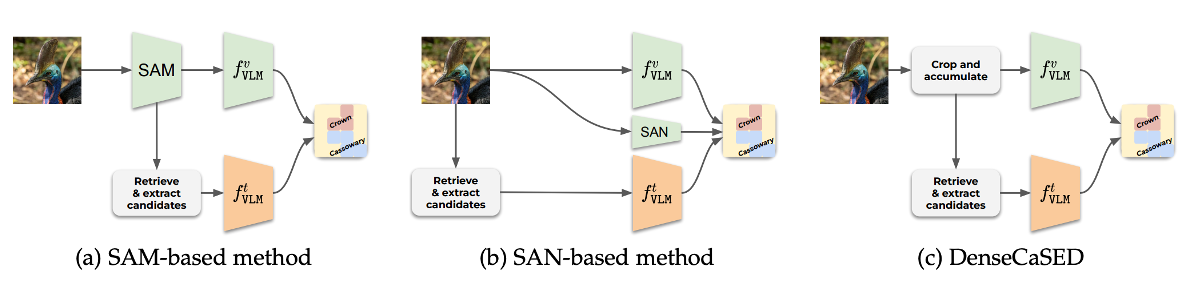 Vocabulary-free Image Classification and Semantic SegmentationAlessandro Conti, Enrico Fini, Massimiliano Mancini, Paolo Rota, Yiming Wang, and Elisa RicciIn Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2026
Vocabulary-free Image Classification and Semantic SegmentationAlessandro Conti, Enrico Fini, Massimiliano Mancini, Paolo Rota, Yiming Wang, and Elisa RicciIn Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2026Large vision-language models revolutionized image classification and semantic segmentation paradigms. However, they typically assume a pre-defined set of categories, or vocabulary, at test time for composing textual prompts. This assumption is impractical in scenarios with unknown or evolving semantic context. Here, we address this issue and introduce the Vocabulary-free Image Classification (VIC) task, which aims to assign a class from an unconstrained language-induced semantic space to an input image without needing a known vocabulary. VIC is challenging due to the vastness of the semantic space, which contains millions of concepts, including fine-grained categories. To address VIC, we propose Category Search from External Databases (CaSED), a training-free method that leverages a pre-trained vision-language model and an external database. CaSED first extracts the set of candidate categories from the most semantically similar captions in the database and then assigns the image to the best-matching candidate category according to the same vision-language model. Furthermore, we demonstrate that CaSED can be applied locally to generate a coarse segmentation mask that classifies image regions, introducing the task of Vocabulary-free Semantic Segmentation. CaSED and its variants outperform other more complex vision-language models, on classification and semantic segmentation benchmarks, while using much fewer parameters.
@inproceedings{conti2026tpami, title = {Vocabulary-free Image Classification and Semantic Segmentation}, author = {Conti, Alessandro and Fini, Enrico and Mancini, Massimiliano and Rota, Paolo and Wang, Yiming and Ricci, Elisa}, booktitle = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)}, year = {2026}, } -
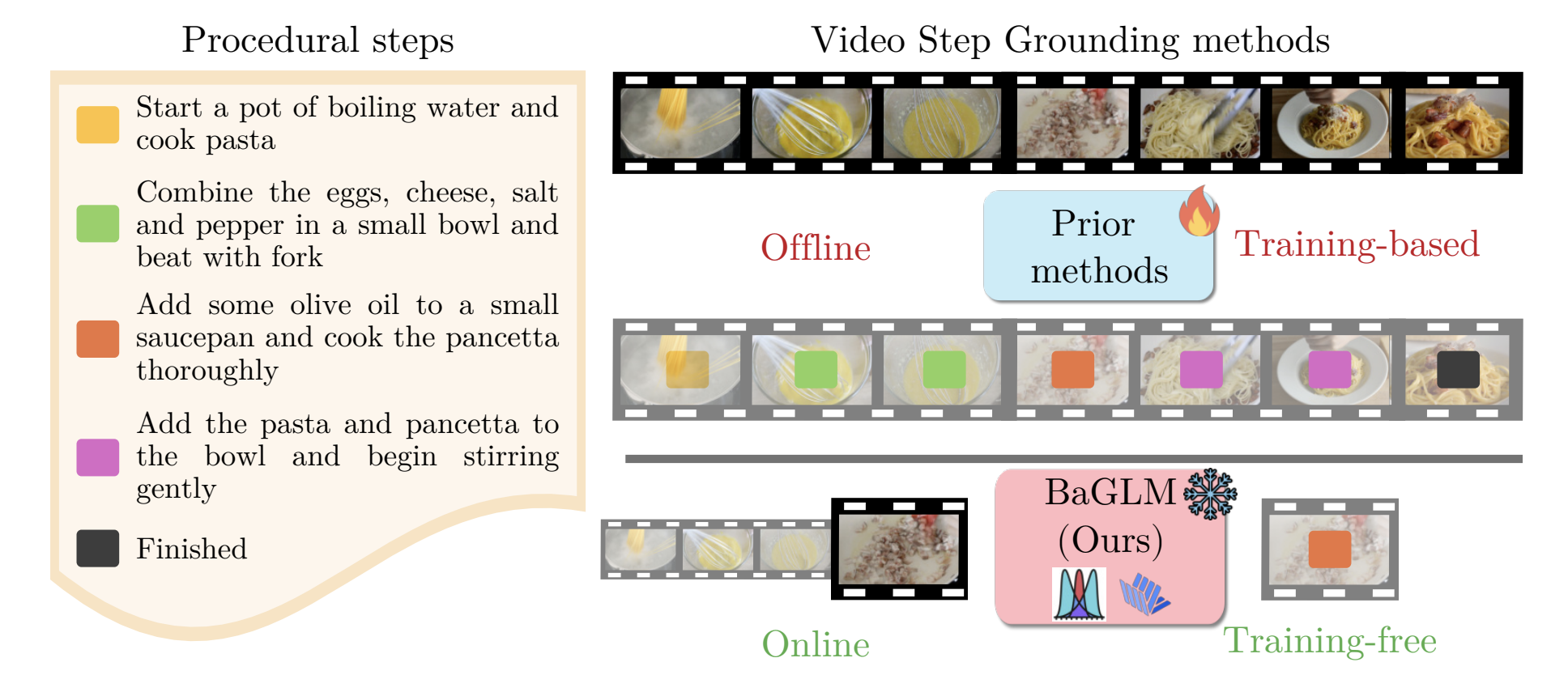 Training-free Online Video Step GroundingLuca Zanella, Massimiliano Mancini, Yiming Wang, Alessio Tonioni, and Elisa RicciIn Proceedings of Neural Information Processing Systems (NeurIPS), 2025
Training-free Online Video Step GroundingLuca Zanella, Massimiliano Mancini, Yiming Wang, Alessio Tonioni, and Elisa RicciIn Proceedings of Neural Information Processing Systems (NeurIPS), 2025Given a task and a set of steps composing it, Video Step Grounding (VSG) aims to detect which steps are performed in a video. Standard approaches for this task require a labeled training set (e.g., with step-level annotations or narrations), which may be costly to collect. Moreover, they process the full video offline, limiting their applications for scenarios requiring online decisions. Thus, in this work, we explore how to perform VSG online and without training. We achieve this by exploiting the zero-shot capabilities of recent Large Multimodal Models (LMMs). In particular, we use LMMs to predict the step associated with a restricted set of frames, without access to the whole video. We show that this online strategy without task-specific tuning outperforms offline and training-based models. Motivated by this finding, we develop Bayesian Grounding with Large Multimodal Models (BAGLM), further injecting knowledge of past frames into the LMM-based predictions. BAGLM exploits Bayesian filtering principles, modeling step transitions via (i) a dependency matrix extracted through large language models and (ii) an estimation of step progress. Experiments on three datasets show superior performance of BAGLM over state-of-the-art training-based offline methods.
@inproceedings{zanella2025baglm, title = {Training-free Online Video Step Grounding}, author = {Zanella, Luca and Mancini, Massimiliano and Wang, Yiming and Tonioni, Alessio and Ricci, Elisa}, booktitle = {Proceedings of Neural Information Processing Systems (NeurIPS)}, year = {2025}, } -
 ConViS-Bench: Estimating Video Similarity Through Semantic ConceptsBenedetta Liberatori, Alessandro Conti, Lorenzo Vaquero, Yiming Wang, Elisa Ricci, and Paolo RotaIn Proceedings of Neural Information Processing Systems (NeurIPS), 2025
ConViS-Bench: Estimating Video Similarity Through Semantic ConceptsBenedetta Liberatori, Alessandro Conti, Lorenzo Vaquero, Yiming Wang, Elisa Ricci, and Paolo RotaIn Proceedings of Neural Information Processing Systems (NeurIPS), 2025What does it mean for two videos to be similar? Videos may appear similar when judged by the actions they depict, yet entirely different if evaluated based on the locations where they were filmed. While humans naturally compare videos by taking different aspects into account, this ability has not been thoroughly studied and presents a challenge for models that often depend on broad global similarity scores. Large Multimodal Models (LMMs) with video understanding capabilities open new opportunities for leveraging natural language in comparative video tasks. We introduce Concept-based Video Similarity estimation (ConViS), a novel task that compares pairs of videos by computing interpretable similarity scores across a predefined set of key semantic concepts. ConViS allows for human-like reasoning about video similarity and enables new applications such as concept-conditioned video retrieval. To support this task, we also introduce ConViS-Bench, a new benchmark comprising carefully annotated video pairs spanning multiple domains. Each pair comes with concept-level similarity scores and textual descriptions of both differences and similarities. Additionally, we benchmark several state-of-the-art models on ConViS, providing insights into their alignment with human judgments. Our results reveal significant performance differences on ConViS, indicating that some concepts present greater challenges for estimating video similarity. We believe that ConViS-Bench will serve as a valuable resource for advancing research in language-driven video understanding.
@inproceedings{liberatori2025convis, title = {ConViS-Bench: Estimating Video Similarity Through Semantic Concepts}, author = {Liberatori, Benedetta and Conti, Alessandro and Vaquero, Lorenzo and Wang, Yiming and Ricci, Elisa and Rota, Paolo}, booktitle = {Proceedings of Neural Information Processing Systems (NeurIPS)}, year = {2025}, } -
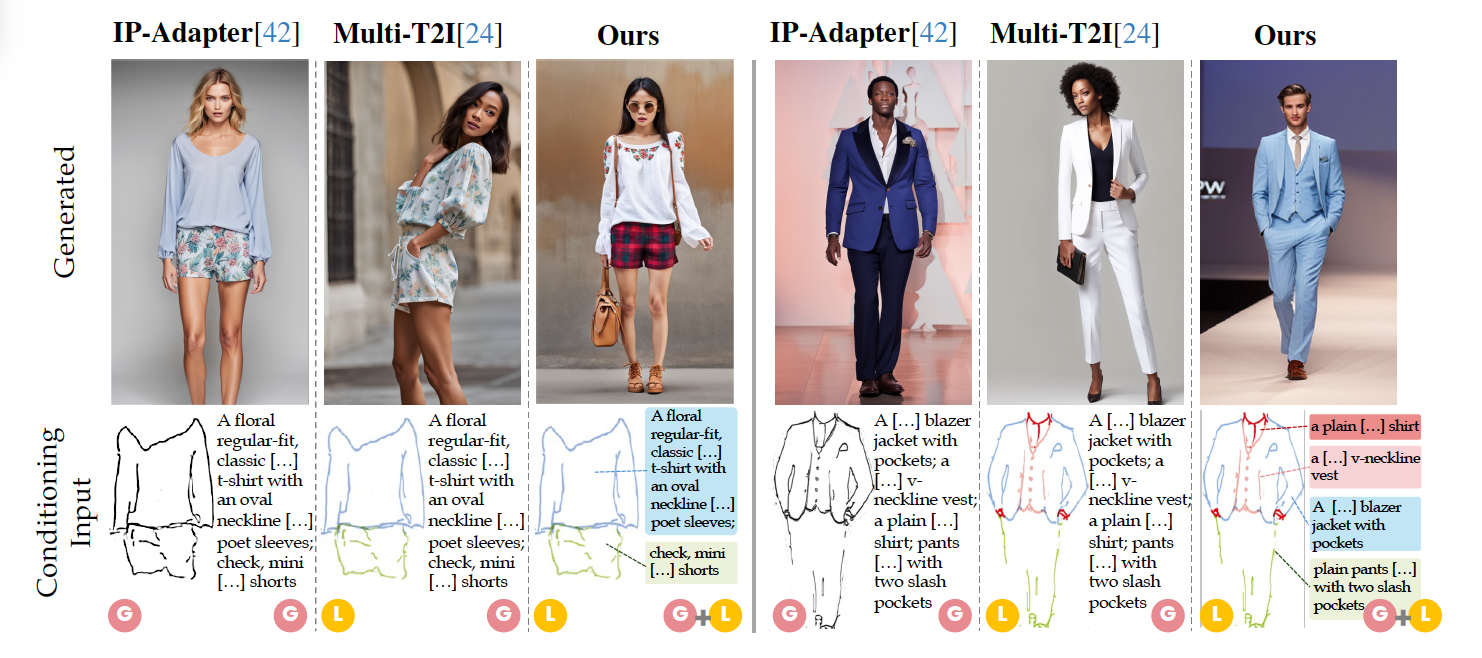 LOTS of Fashion! Multi-Conditioning for Image Generation via Sketch-Text PairingFederico Girella, Davide Talon, Ziyue Liu, Zanxi Ruan, Yiming Wang, and Marco CristaniIn Proceedings of International Conference on Computer Vision (ICCV), 2025
LOTS of Fashion! Multi-Conditioning for Image Generation via Sketch-Text PairingFederico Girella, Davide Talon, Ziyue Liu, Zanxi Ruan, Yiming Wang, and Marco CristaniIn Proceedings of International Conference on Computer Vision (ICCV), 2025Fashion design is a complex creative process that blends visual and textual expressions. Designers convey ideas through sketches, which define spatial structure and design elements, and textual descriptions, capturing material, texture, and stylistic details. In this paper, we present LOcalized Text and Sketch (LOTS), an approach for compositional sketch-text based generation of complete fashion outlooks. LOTS leverages a global description with paired localized sketch + text information for conditioning and introduces a novel multistep-based merging strategy for diffusion adaptation. First, a Modularized Pair-Centric representation encodes sketches and text into a shared latent space while preserving independent localized features; then, a Diffusion Pair Guidance phase integrates both local and global conditioning via attention-based guidance within the diffusion model’s multi-step denoising process. To validate our method, we build on Fashionpedia to release Sketchy, the first fashion dataset where multiple sketch-text pairs are provided per image. Quantitative results show LOTS achieves state-of-the-art image generation performance on both global and localized metrics, while qualitative examples and a human evaluation study highlight its unprecedented level of design customization.
@inproceedings{girella2025lots, title = {LOTS of Fashion! Multi-Conditioning for Image Generation via Sketch-Text Pairing}, author = {Girella, Federico and Talon, Davide and Liu, Ziyue and Ruan, Zanxi and Wang, Yiming and Cristani, Marco}, booktitle = {Proceedings of International Conference on Computer Vision (ICCV)}, year = {2025}, } -
 On large multimodal models as open-world image classifiersAlessandro Conti, Massimiliano Mancini, Enrico Fini, Yiming Wang, Paolo Rota, and Elisa RicciIn Proceedings of International Conference on Computer Vision (ICCV), 2025
On large multimodal models as open-world image classifiersAlessandro Conti, Massimiliano Mancini, Enrico Fini, Yiming Wang, Paolo Rota, and Elisa RicciIn Proceedings of International Conference on Computer Vision (ICCV), 2025Traditional image classification requires a predefined list of semantic categories. In contrast, Large Multimodal Models (LMMs) can sidestep this requirement by classifying images directly using natural language (e.g., answering the prompt "What is the main object in the image?"). Despite this remarkable capability, most existing studies on LMM classification performance are surprisingly limited in scope, often assuming a closed-world setting with a predefined set of categories. In this work, we address this gap by thoroughly evaluating LMM classification performance in a truly open-world setting. We first formalize the task and introduce an evaluation protocol, defining various metrics to assess the alignment between predicted and ground truth classes. We then evaluate 13 models across 10 benchmarks, encompassing prototypical, non-prototypical, fine-grained, and very fine-grained classes, demonstrating the challenges LMMs face in this task. Further analyses based on the proposed metrics reveal the types of errors LMMs make, highlighting challenges related to granularity and fine-grained capabilities, showing how tailored prompting and reasoning can alleviate them.
@inproceedings{conti2025large, title = {On large multimodal models as open-world image classifiers}, author = {Conti, Alessandro and Mancini, Massimiliano and Fini, Enrico and Wang, Yiming and Rota, Paolo and Ricci, Elisa}, booktitle = {Proceedings of International Conference on Computer Vision (ICCV)}, year = {2025}, } -
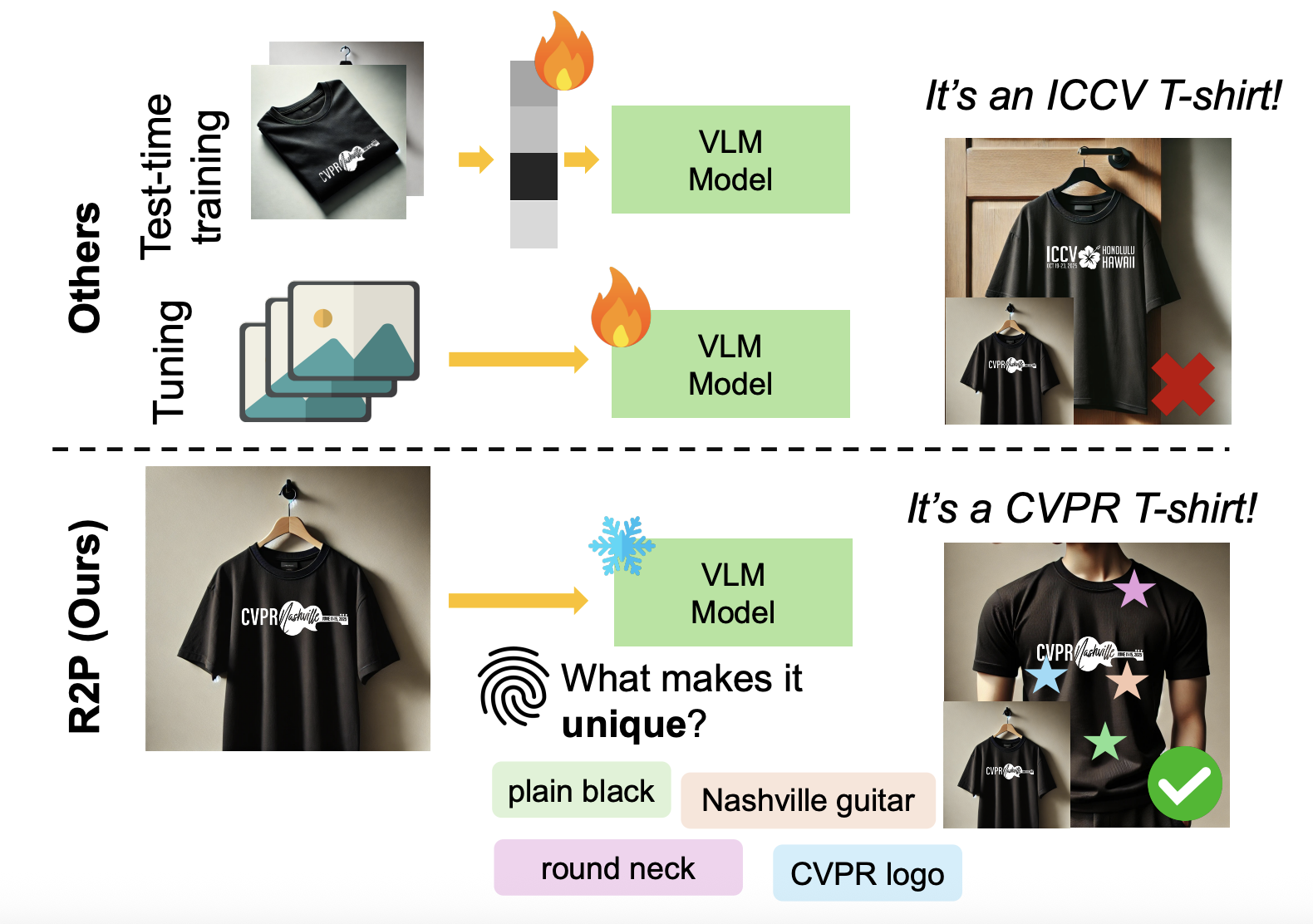 Training-Free Personalization via Retrieval and Reasoning on FingerprintsDeepayan Das, Davide Talon, Yiming Wang, Massimiliano Mancini, and Elisa RicciIn Proceedings of International Conference on Computer Vision (ICCV), 2025
Training-Free Personalization via Retrieval and Reasoning on FingerprintsDeepayan Das, Davide Talon, Yiming Wang, Massimiliano Mancini, and Elisa RicciIn Proceedings of International Conference on Computer Vision (ICCV), 2025Vision Language Models (VLMs) have lead to major improvements in multimodal reasoning, yet they still struggle to understand user-specific concepts. Existing personalization methods address this limitation but heavily rely on training procedures, that can be either costly or unpleasant to individual users. We depart from existing work, and for the first time explore the training-free setting in the context of personalization. We propose a novel method, Retrieval and Reasoning for Personalization (R2P), leveraging internal knowledge of VLMs. First, we leverage VLMs to extract the concept fingerprint, i.e., key attributes uniquely defining the concept within its semantic class. When a query arrives, the most similar fingerprints are retrieved and scored via chain-of-thought-reasoning. To reduce the risk of hallucinations, the scores are validated through cross-modal verification at the attribute level: in case of a discrepancy between the scores, R2P refines the concept association via pairwise multimodal matching, where the retrieved fingerprints and their images are directly compared with the query. We validate R2P on two publicly available benchmarks and a newly introduced dataset, Personal Concepts with Visual Ambiguity (PerVA), for concept identification highlighting challenges in visual ambiguity. R2P consistently outperforms state-of-the-art approaches on various downstream tasks across all benchmarks. Code will be available upon acceptance.
@inproceedings{das2025training, title = {Training-Free Personalization via Retrieval and Reasoning on Fingerprints}, author = {Das, Deepayan and Talon, Davide and Wang, Yiming and Mancini, Massimiliano and Ricci, Elisa}, booktitle = {Proceedings of International Conference on Computer Vision (ICCV)}, year = {2025}, } -
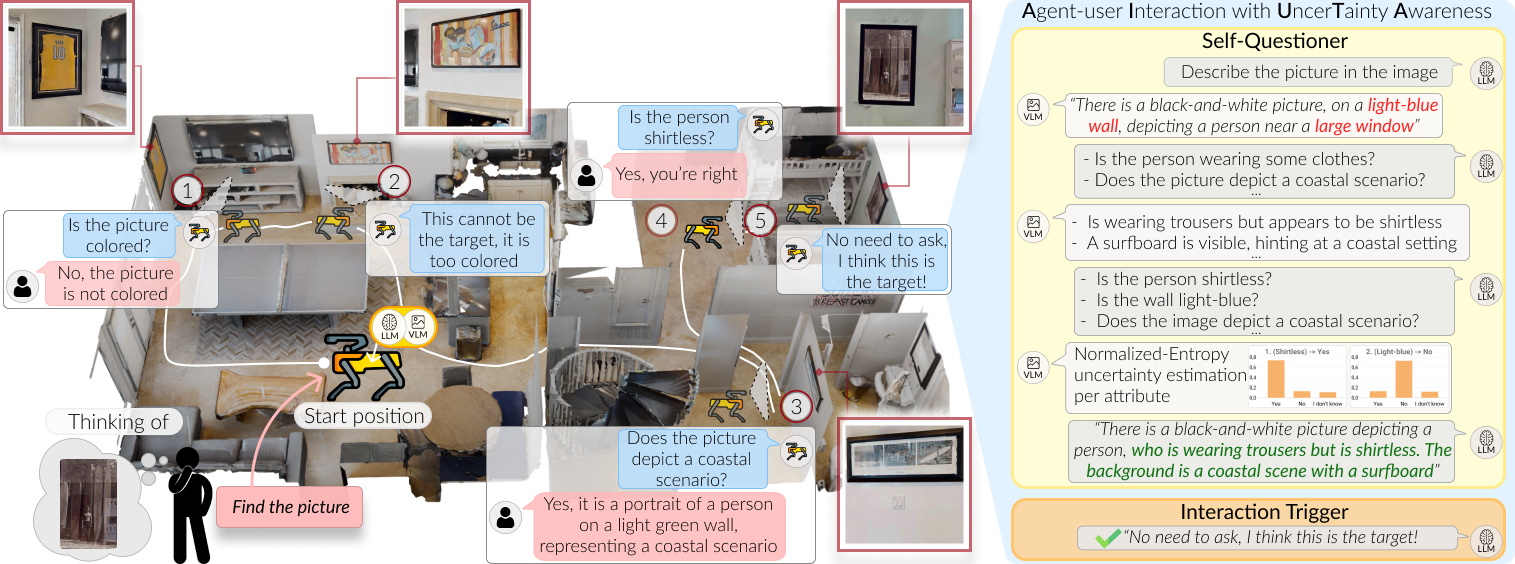 Collaborative Instance Object Navigation: Leveraging Uncertainty-Awareness to Minimize Human-Agent DialoguesFrancesco Taioli, Edoardo Zorzi, Gianni Franchi, Alberto Castellini, Alessandro Farinelli, Marco Cristani, and Yiming WangIn Proceedings of International Conference on Computer Vision (ICCV), 2025
Collaborative Instance Object Navigation: Leveraging Uncertainty-Awareness to Minimize Human-Agent DialoguesFrancesco Taioli, Edoardo Zorzi, Gianni Franchi, Alberto Castellini, Alessandro Farinelli, Marco Cristani, and Yiming WangIn Proceedings of International Conference on Computer Vision (ICCV), 2025Language-driven instance object navigation assumes that human users initiate the task by providing a detailed description of the target instance to the embodied agent. While this description is crucial for distinguishing the target from visually similar instances in a scene, providing it prior to navigation can be demanding for human. To bridge this gap, we introduce Collaborative Instance object Navigation (CoIN), a new task setting where the agent actively resolve uncertainties about the target instance during navigation in natural, template-free, open-ended dialogues with human. We propose a novel training-free method, Agent-user Interaction with UncerTainty Awareness (AIUTA), which operates independently from the navigation policy, and focuses on the human-agent interaction reasoning with Vision-Language Models (VLMs) and Large Language Models (LLMs). First, upon object detection, a Self-Questioner model initiates a self-dialogue within the agent to obtain a complete and accurate observation description with a novel uncertainty estimation technique. Then, an Interaction Trigger module determines whether to ask a question to the human, continue or halt navigation, minimizing user input. For evaluation, we introduce CoIN-Bench, with a curated dataset designed for challenging multi-instance scenarios. CoIN-Bench supports both online evaluation with humans and reproducible experiments with simulated user-agent interactions. On CoIN-Bench, we show that AIUTA serves as a competitive baseline, while existing language-driven instance navigation methods struggle in complex multi-instance scenes.
@inproceedings{taioli2025collaborative, title = {Collaborative Instance Object Navigation: Leveraging Uncertainty-Awareness to Minimize Human-Agent Dialogues}, author = {Taioli, Francesco and Zorzi, Edoardo and Franchi, Gianni and Castellini, Alberto and Farinelli, Alessandro and Cristani, Marco and Wang, Yiming}, booktitle = {Proceedings of International Conference on Computer Vision (ICCV)}, year = {2025}, } -
 Free-form language-based robotic reasoning and graspingRunyu Jiao, Alice Fasoli, Francesco Giuliari, Matteo Bortolon, Sergio Povoli, Guofeng Mei, Yiming Wang, and Fabio PoiesiIn Proceedings of International Conference on Intelligent Robots and Systems (IROS), 2025
Free-form language-based robotic reasoning and graspingRunyu Jiao, Alice Fasoli, Francesco Giuliari, Matteo Bortolon, Sergio Povoli, Guofeng Mei, Yiming Wang, and Fabio PoiesiIn Proceedings of International Conference on Intelligent Robots and Systems (IROS), 2025Performing robotic grasping from a cluttered bin based on human instructions is a challenging task, as it requires understanding both the nuances of free-form language and the spatial relationships between objects. Vision-Language Models (VLMs) trained on web-scale data, such as GPT-4o, have demonstrated remarkable reasoning capabilities across both text and images. But can they truly be used for this task in a zero-shot setting? And what are their limitations? In this paper, we explore these research questions via the free-form language-based robotic grasping task, and propose a novel method, FreeGrasp, leveraging the pre-trained VLMs’ world knowledge to reason about human instructions and object spatial arrangements. Our method detects all objects as keypoints and uses these keypoints to annotate marks on images, aiming to facilitate GPT-4o’s zero-shot spatial reasoning. This allows our method to determine whether a requested object is directly graspable or if other objects must be grasped and removed first. Since no existing dataset is specifically designed for this task, we introduce a synthetic dataset FreeGraspData by extending the MetaGraspNetV2 dataset with human-annotated instructions and ground-truth grasping sequences. We conduct extensive analyses with both FreeGraspData and real-world validation with a gripper-equipped robotic arm, demonstrating state-of-the-art performance in grasp reasoning and execution.
@inproceedings{jiao2025free, title = {Free-form language-based robotic reasoning and grasping}, author = {Jiao, Runyu and Fasoli, Alice and Giuliari, Francesco and Bortolon, Matteo and Povoli, Sergio and Mei, Guofeng and Wang, Yiming and Poiesi, Fabio}, booktitle = {Proceedings of International Conference on Intelligent Robots and Systems (IROS)}, year = {2025}, } -
 PerLA: Perceptive 3D language assistantGuofeng Mei, Wei Lin, Luigi Riz, Yujiao Wu, Fabio Poiesi, and Yiming WangIn Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), 2025
PerLA: Perceptive 3D language assistantGuofeng Mei, Wei Lin, Luigi Riz, Yujiao Wu, Fabio Poiesi, and Yiming WangIn Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), 2025Enabling Large Language Models (LLMs) to understand the 3D physical world is an emerging yet challenging research direction. Current strategies for processing point clouds typically downsample the scene or divide it into smaller parts for separate analysis. However, both approaches risk losing key local details or global contextual information. In this paper, we introduce PerLA, a 3D language assistant designed to be more perceptive to both details and context, making visual representations more informative for the LLM. PerLA captures high-resolution (local) details in parallel from different point cloud areas and integrates them with (global) context obtained from a lower-resolution whole point cloud. We present a novel algorithm that preserves point cloud locality through the Hilbert curve and effectively aggregates local-to-global information via cross-attention and a graph neural network. Lastly, we introduce a novel loss for local representation consensus to promote training stability. PerLA outperforms state-of-the-art 3D language assistants, with gains of up to +1.34 CiDEr on ScanQA for question answering, and +4.22 on ScanRefer and +3.88 on Nr3D for dense captioning.
@inproceedings{mei2025perla, title = {PerLA: Perceptive 3D language assistant}, author = {Mei, Guofeng and Lin, Wei and Riz, Luigi and Wu, Yujiao and Poiesi, Fabio and Wang, Yiming}, booktitle = {Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2025}, } -
 Collaborative Neural PaintingNicola Dall’Asen, Willi Menapace, Elia Peruzzo, Enver Sangineto, Yiming Wang, and Elisa RicciComputer Vision and Image Understanding (CVIU), 2025
Collaborative Neural PaintingNicola Dall’Asen, Willi Menapace, Elia Peruzzo, Enver Sangineto, Yiming Wang, and Elisa RicciComputer Vision and Image Understanding (CVIU), 2025The process of painting fosters creativity and rational planning. However, existing generative AI mostly focuses on producing visually pleasant artworks, without emphasizing the painting process. We introduce a novel task, Collaborative Neural Painting (CNP), to facilitate collaborative art painting generation between humans and machines. Given any number of user-input brushstrokes as the context or just the desired object class, CNP should produce a sequence of strokes supporting the completion of a coherent painting. Importantly, the process can be gradual and iterative, so allowing users’ modifications at any phase until the completion. Moreover, we propose to solve this task using a painting representation based on a sequence of parametrized strokes, which makes it easy both editing and composition operations. These parametrized strokes are processed by a Transformer-based architecture with a novel attention mechanism to model the relationship between the input strokes and the strokes to complete. We also propose a new masking scheme to reflect the interactive nature of CNP and adopt diffusion models as the basic learning process for its effectiveness and diversity in the generative field. Finally, to develop and validate methods on the novel task, we introduce a new dataset of painted objects and an evaluation protocol to benchmark CNP both quantitatively and qualitatively. We demonstrate the effectiveness of our approach and the potential of the CNP task as a promising avenue for future research.
@article{dall2025collaborative, title = {Collaborative Neural Painting}, author = {Dall'Asen, Nicola and Menapace, Willi and Peruzzo, Elia and Sangineto, Enver and Wang, Yiming and Ricci, Elisa}, journal = {Computer Vision and Image Understanding (CVIU)}, year = {2025}, } -
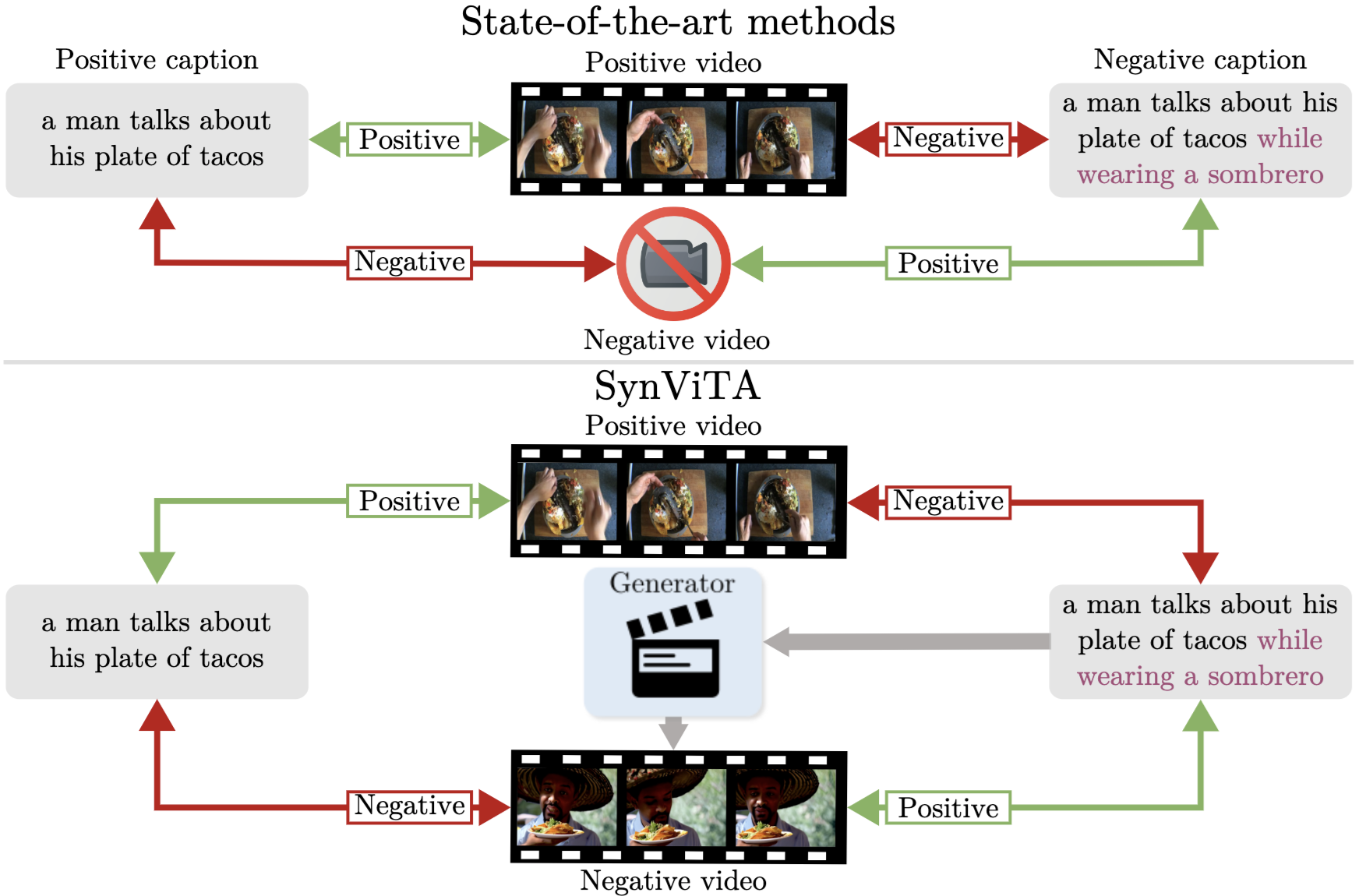 Can Text-to-Video Generation help Video-Language Alignment?Luca Zanella, Massimiliano Mancini, Willi Menapace, Sergey Tulyakov, Yiming Wang, and Elisa RicciIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
Can Text-to-Video Generation help Video-Language Alignment?Luca Zanella, Massimiliano Mancini, Willi Menapace, Sergey Tulyakov, Yiming Wang, and Elisa RicciIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025Recent video-language alignment models are trained on sets of videos, each with an associated positive caption and a negative caption generated by large language models. A problem with this procedure is that negative captions may introduce linguistic biases, i.e., concepts are seen only as negatives and never associated with a video. While a solution would be to collect videos for the negative captions, existing databases lack the fine-grained variations needed to cover all possible negatives. In this work, we study whether synthetic videos can help to overcome this issue. Our preliminary analysis with multiple generators shows that, while promising on some tasks, synthetic videos harm the performance of the model on others. We hypothesize this issue is linked to noise (semantic and visual) in the generated videos and develop a method, SynViTA, that accounts for those. SynViTA dynamically weights the contribution of each synthetic video based on how similar its target caption is w.r.t. the real counterpart. Moreover, a semantic consistency loss makes the model focus on fine-grained differences across captions, rather than differences in video appearance. Experiments show that, on average, SynViTA improves over existing methods on VideoCon test sets and SSv2-Temporal, SSv2-Events, and ATP-Hard benchmarks, being a first promising step for using synthetic videos when learning video-language models.
@inproceedings{zanella2025synvita, title = {Can Text-to-Video Generation help Video-Language Alignment?}, author = {Zanella, Luca and Mancini, Massimiliano and Menapace, Willi and Tulyakov, Sergey and Wang, Yiming and Ricci, Elisa}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, year = {2025}, } -
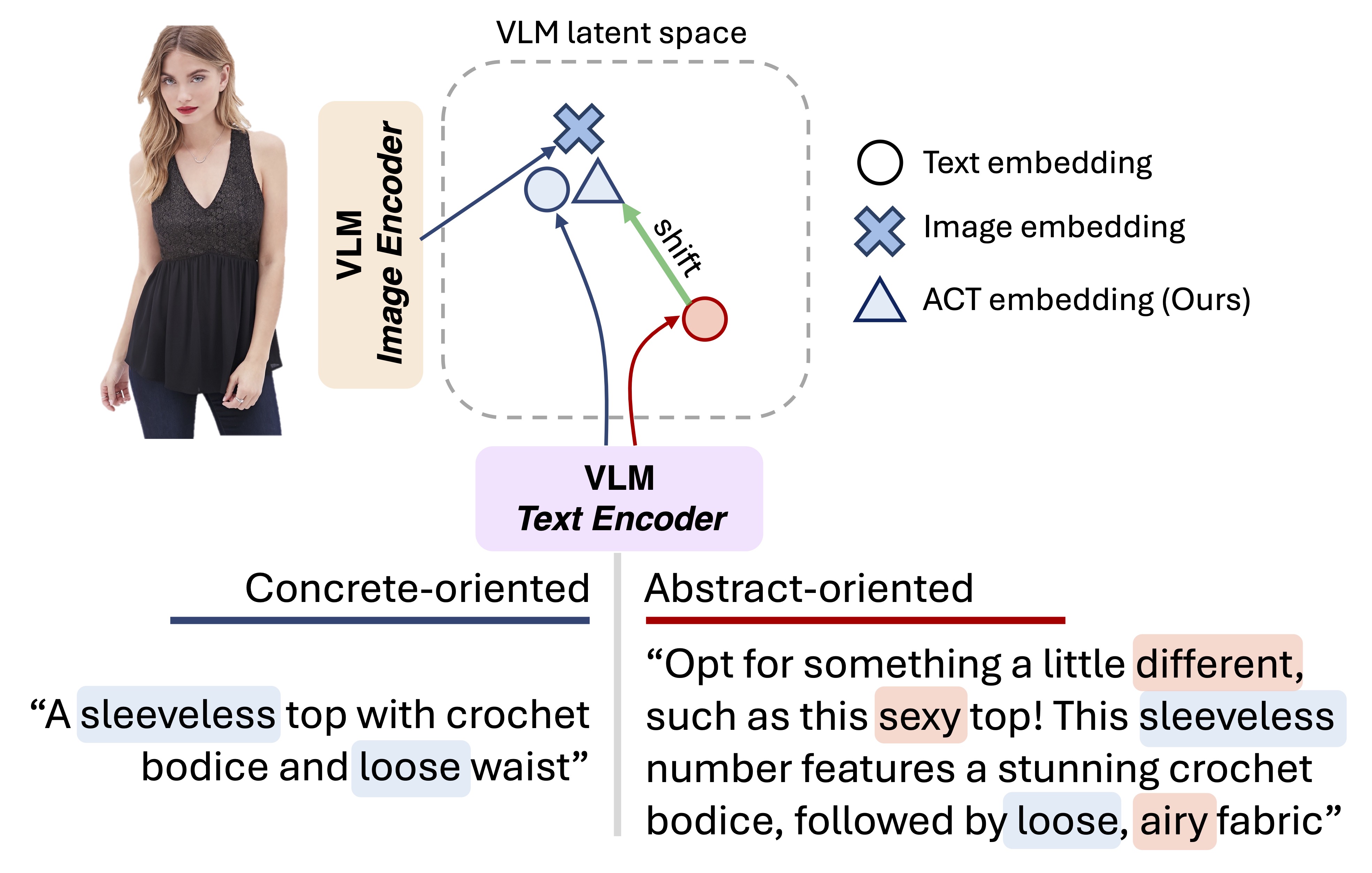 Seeing the Abstract: Translating the Abstract Language for Vision Language ModelsDavide Talon, Federico Girella, Ziyue Liu, Marco Cristani, and Yiming WangIn Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Seeing the Abstract: Translating the Abstract Language for Vision Language ModelsDavide Talon, Federico Girella, Ziyue Liu, Marco Cristani, and Yiming WangIn Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), 2025Natural language goes beyond dryly describing visual content. It contains rich abstract concepts to express feeling, creativity and properties that cannot be directly perceived. Yet, current research in Vision Language Models (VLMs) has not shed light on abstract-oriented language. Our research breaks new ground by uncovering its wide presence and under-estimated value, with extensive analysis. Particularly, we focus our investigation on the fashion domain, a highly-representative field with abstract expressions. By analyzing recent large-scale multimodal fashion datasets, we find that abstract terms have a dominant presence, rivaling the concrete ones, providing novel information, and being useful in the retrieval task. However, a critical challenge emerges: current general-purpose or fashion-specific VLMs are pre-trained with databases that lack sufficient abstract words in their text corpora, thus hindering their ability to effectively represent abstract-oriented language. We propose a training-free and model-agnostic method, Abstract-to-Concrete Translator (ACT), to shift abstract representations towards well-represented concrete ones in the VLM latent space, using pre-trained models and existing multimodal databases. On the text-to-image retrieval task, despite being training-free, ACT outperforms the fine-tuned VLMs in both same- and cross-dataset settings, exhibiting its effectiveness with a strong generalization capability. Moreover, the improvement introduced by ACT is consistent with various VLMs, making it a plug-and-play solution.
@inproceedings{talon2025seeing, title = {Seeing the Abstract: Translating the Abstract Language for Vision Language Models}, author = {Talon, Davide and Girella, Federico and Liu, Ziyue and Cristani, Marco and Wang, Yiming}, booktitle = {Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2025}, } -
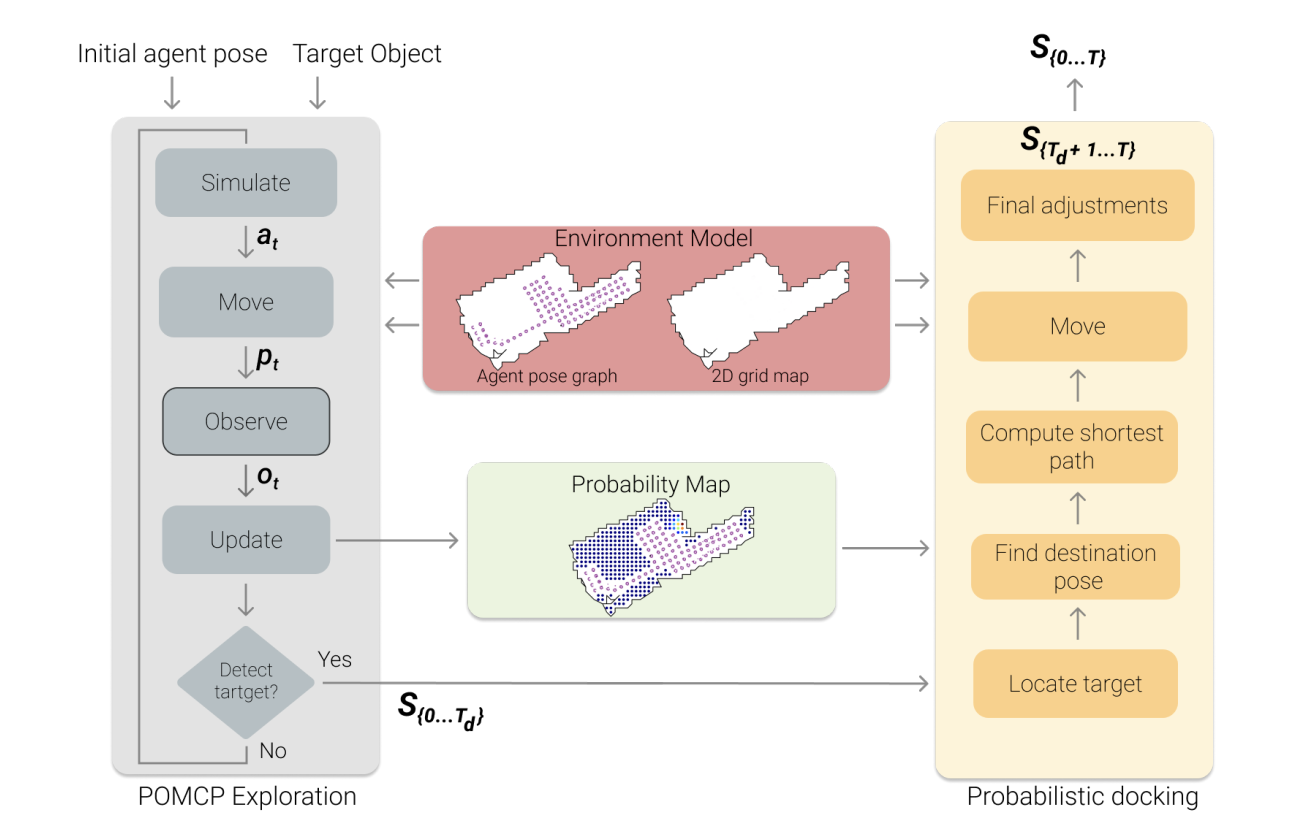 Unsupervised active visual search with monte carlo planning under uncertain detectionsFrancesco Taioli, Francesco Giuliari, Yiming Wang, Riccardo Berra, Alberto Castellini, Alessio Del Bue, Alessandro Farinelli, Marco Cristani, and Francesco SettiTransactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024
Unsupervised active visual search with monte carlo planning under uncertain detectionsFrancesco Taioli, Francesco Giuliari, Yiming Wang, Riccardo Berra, Alberto Castellini, Alessio Del Bue, Alessandro Farinelli, Marco Cristani, and Francesco SettiTransactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024We propose a solution for Active Visual Search of objects in an environment, whose 2D floor map is the only known information. Our solution has three key features that make it more plausible and robust to detector failures compared to state-of-the-art methods: (i) it is unsupervised as it does not need any training sessions. (ii) During the exploration, a probability distribution on the 2D floor map is updated according to an intuitive mechanism, while an improved belief update increases the effectiveness of the agent’s exploration. (iii) We incorporate the awareness that an object detector may fail into the aforementioned probability modelling by exploiting the success statistics of a specific detector. Our solution is dubbed POMP-BE-PD (Pomcp-based Online Motion Planning with Belief by Exploration and Probabilistic Detection). It uses the current pose of an agent and an RGB-D observation to learn an optimal search policy, exploiting a POMDP solved by a Monte-Carlo planning approach. On the Active Vision Database benchmark, we increase the average success rate over all the environments by a significant 35% while decreasing the average path length by 4% with respect to competing methods. Thus, our results are state-of-the-art, even without using any training procedure.
@article{taioli2024unsupervised, title = {Unsupervised active visual search with monte carlo planning under uncertain detections}, author = {Taioli, Francesco and Giuliari, Francesco and Wang, Yiming and Berra, Riccardo and Castellini, Alberto and Del Bue, Alessio and Farinelli, Alessandro and Cristani, Marco and Setti, Francesco}, journal = {Transactions on Pattern Analysis and Machine Intelligence (TPAMI)}, year = {2024}, } -
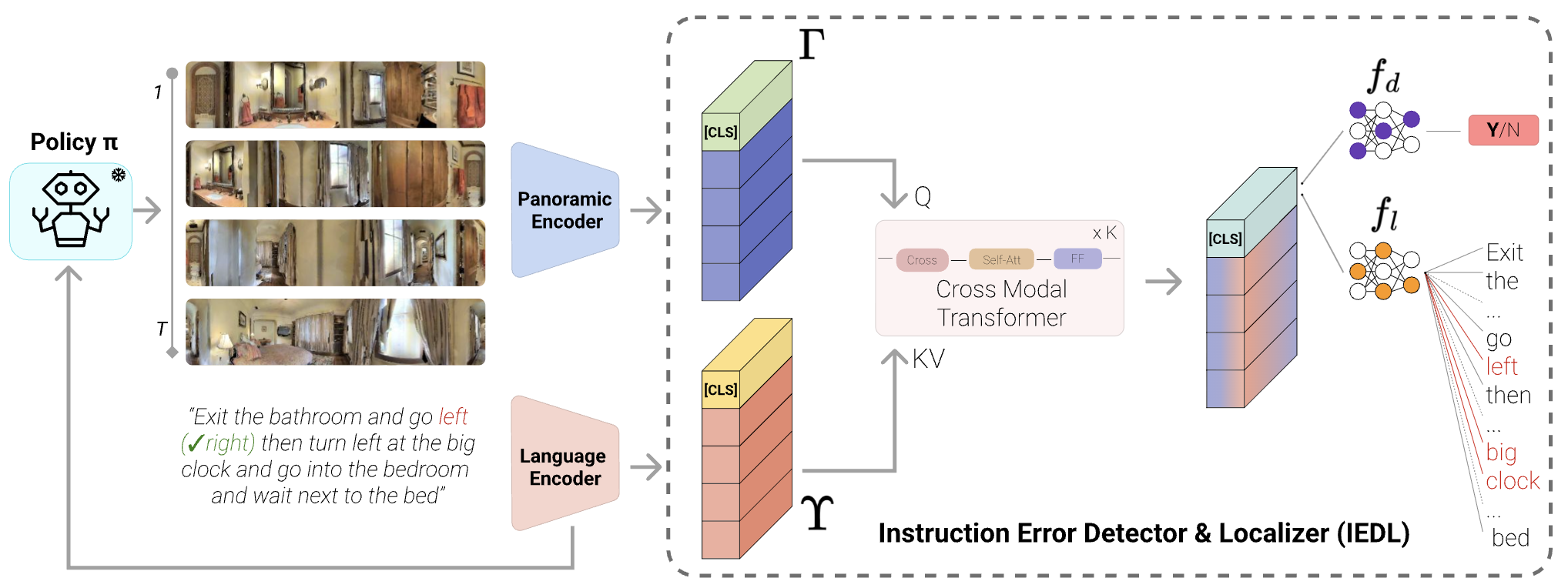 Mind the error! detection and localization of instruction errors in vision-and-language navigationFrancesco Taioli, Stefano Rosa, Alberto Castellini, Lorenzo Natale, Alessio Del Bue, Alessandro Farinelli, Marco Cristani, and Yiming WangIn Proceedings of International Conference on Intelligent Robots and Systems (IROS), 2024
Mind the error! detection and localization of instruction errors in vision-and-language navigationFrancesco Taioli, Stefano Rosa, Alberto Castellini, Lorenzo Natale, Alessio Del Bue, Alessandro Farinelli, Marco Cristani, and Yiming WangIn Proceedings of International Conference on Intelligent Robots and Systems (IROS), 2024Low-resource domains, characterized by scarce data and annotations, present significant challenges for language and visual understanding tasks, with the latter much under-explored in the literature. Recent advancements in Vision-Language Models (VLM) have shown promising results in high-resource domains but fall short in low-resource concepts that are under-represented (e.g. only a handful of images per category) in the pre-training set. We tackle the challenging task of zero-shot low-resource image classification from a novel perspective. By leveraging a retrieval-based strategy, we achieve this in a training-free fashion. Specifically, our method, named CoRE (Combination of Retrieval Enrichment), enriches the representation of both query images and class prototypes by retrieving relevant textual information from large web-crawled databases. This retrieval-based enrichment significantly boosts classification performance by incorporating the broader contextual information relevant to the specific class. We validate our method on a newly established benchmark covering diverse low-resource domains, including medical imaging, rare plants, and circuits. Our experiments demonstrate that CoRE outperforms existing state-of-the-art methods that rely on synthetic data generation and model fine-tuning.
@inproceedings{taioli2024mind, title = {Mind the error! detection and localization of instruction errors in vision-and-language navigation}, author = {Taioli, Francesco and Rosa, Stefano and Castellini, Alberto and Natale, Lorenzo and Del Bue, Alessio and Farinelli, Alessandro and Cristani, Marco and Wang, Yiming}, booktitle = {Proceedings of International Conference on Intelligent Robots and Systems (IROS)}, year = {2024}, } -
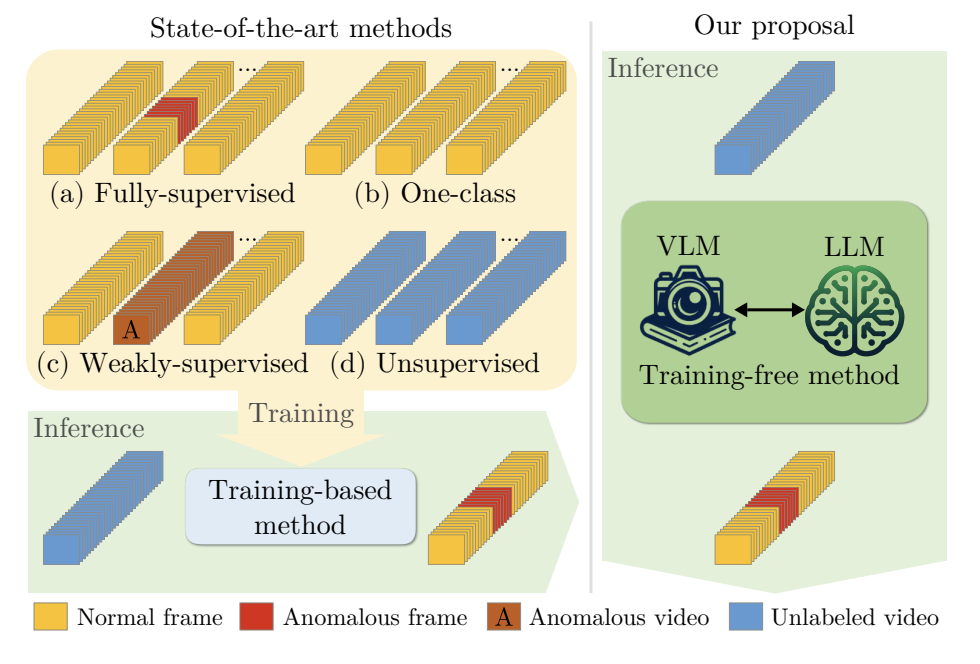 Harnessing Large Language Models for Training-free Video Anomaly DetectionLuca Zanella, Willi Menapace, Massimiliano Mancini, Yiming Wang, and Elisa RicciIn Proceedings of IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), 2024
Harnessing Large Language Models for Training-free Video Anomaly DetectionLuca Zanella, Willi Menapace, Massimiliano Mancini, Yiming Wang, and Elisa RicciIn Proceedings of IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), 2024Video anomaly detection (VAD) aims to temporally locate abnormal events in a video. Existing works mostly rely on training deep models to learn the distribution of normality with either video-level supervision, one-class supervision, or in an unsupervised setting. Training-based methods are prone to be domain-specific, thus being costly for practical deployment as any domain change will involve data collection and model training. In this paper, we radically depart from previous efforts and propose LAnguage-based VAD (LAVAD), a method tackling VAD in a novel, training-free paradigm, exploiting the capabilities of pre-trained large language models (LLMs) and existing vision-language models (VLMs). We leverage VLM-based captioning models to generate textual descriptions for each frame of any test video. With the textual scene description, we then devise a prompting mechanism to unlock the capability of LLMs in terms of temporal aggregation and anomaly score estimation, turning LLMs into an effective video anomaly detector. We further leverage modality-aligned VLMs and propose effective techniques based on cross-modal similarity for cleaning noisy captions and refining the LLM-based anomaly scores. We evaluate LAVAD on two large datasets featuring real-world surveillance scenarios (UCF-Crime and XD-Violence), showing that it outperforms both unsupervised and one-class methods without requiring any training or data collection.
@inproceedings{zanella2024harnessing, title = {Harnessing Large Language Models for Training-free Video Anomaly Detection}, author = {Zanella, Luca and Menapace, Willi and Mancini, Massimiliano and Wang, Yiming and Ricci, Elisa}, booktitle = {Proceedings of IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR)}, year = {2024}, } -
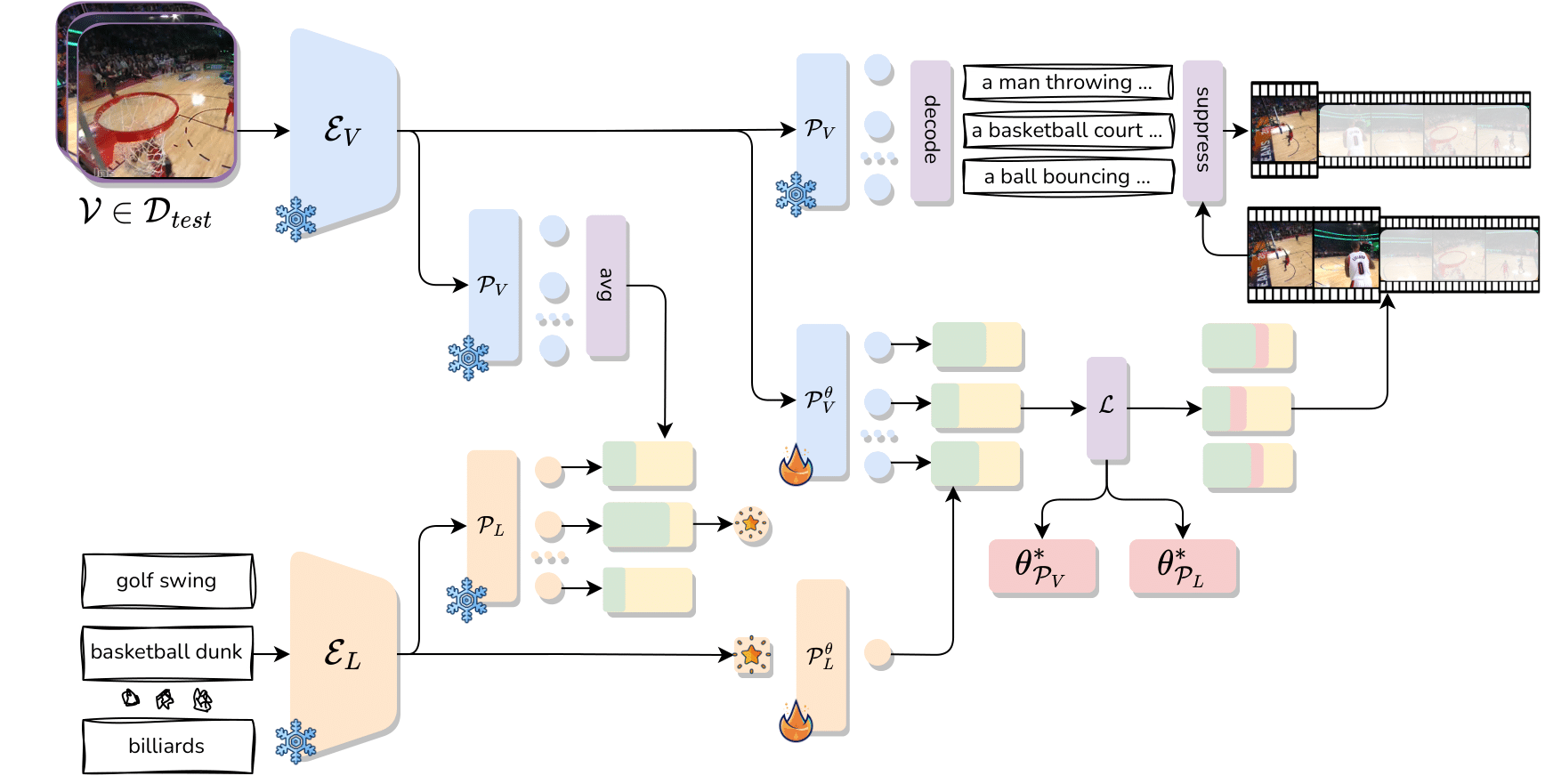 Test-Time Zero-Shot Temporal Action LocalizationBenedetta Liberatori, Alessandro Conti, Paolo Rota, Yiming Wang, and Elisa RicciIn Proceedings of IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), 2024
Test-Time Zero-Shot Temporal Action LocalizationBenedetta Liberatori, Alessandro Conti, Paolo Rota, Yiming Wang, and Elisa RicciIn Proceedings of IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), 2024Zero-Shot Temporal Action Localization (ZS-TAL) seeks to identify and locate actions in untrimmed videos unseen during training. Existing ZS-TAL methods involve fine-tuning a model on a large amount of annotated training data. While effective, training-based ZS-TAL approaches assume the availability of labeled data for supervised learning, which can be impractical in some applications. Furthermore, the training process naturally induces a domain bias into the learned model, which may adversely affect the model’s generalization ability to arbitrary videos. These considerations prompt us to approach the ZS-TAL problem from a radically novel perspective, relaxing the requirement for training data. To this aim, we introduce a novel method that performs Test-Time adaptation for Temporal Action Localization (T3AL). In a nutshell, T3AL adapts a pre-trained Vision and Language Model (VLM) at inference time on a sample basis. T3AL operates in three steps. First, a video-level pseudo-label of the action category is computed by aggregating information from the entire video. Then, action localization is performed adopting a novel procedure inspired by self-supervised learning. Finally, frame-level textual descriptions extracted with a state-of-the-art captioning model are employed for refining the action region proposals. We validate the effectiveness of by conducting experiments on the THUMOS14 and the ActivityNet-v1.3 datasets. Our results demonstrate that significantly outperforms zero-shot baselines based on state-of-the-art VLMs, confirming the benefit of a test-time adaptation approach.
@inproceedings{liberatori2024test, title = {Test-Time Zero-Shot Temporal Action Localization}, author = {Liberatori, Benedetta and Conti, Alessandro and Rota, Paolo and Wang, Yiming and Ricci, Elisa}, booktitle = {Proceedings of IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR)}, year = {2024}, } -
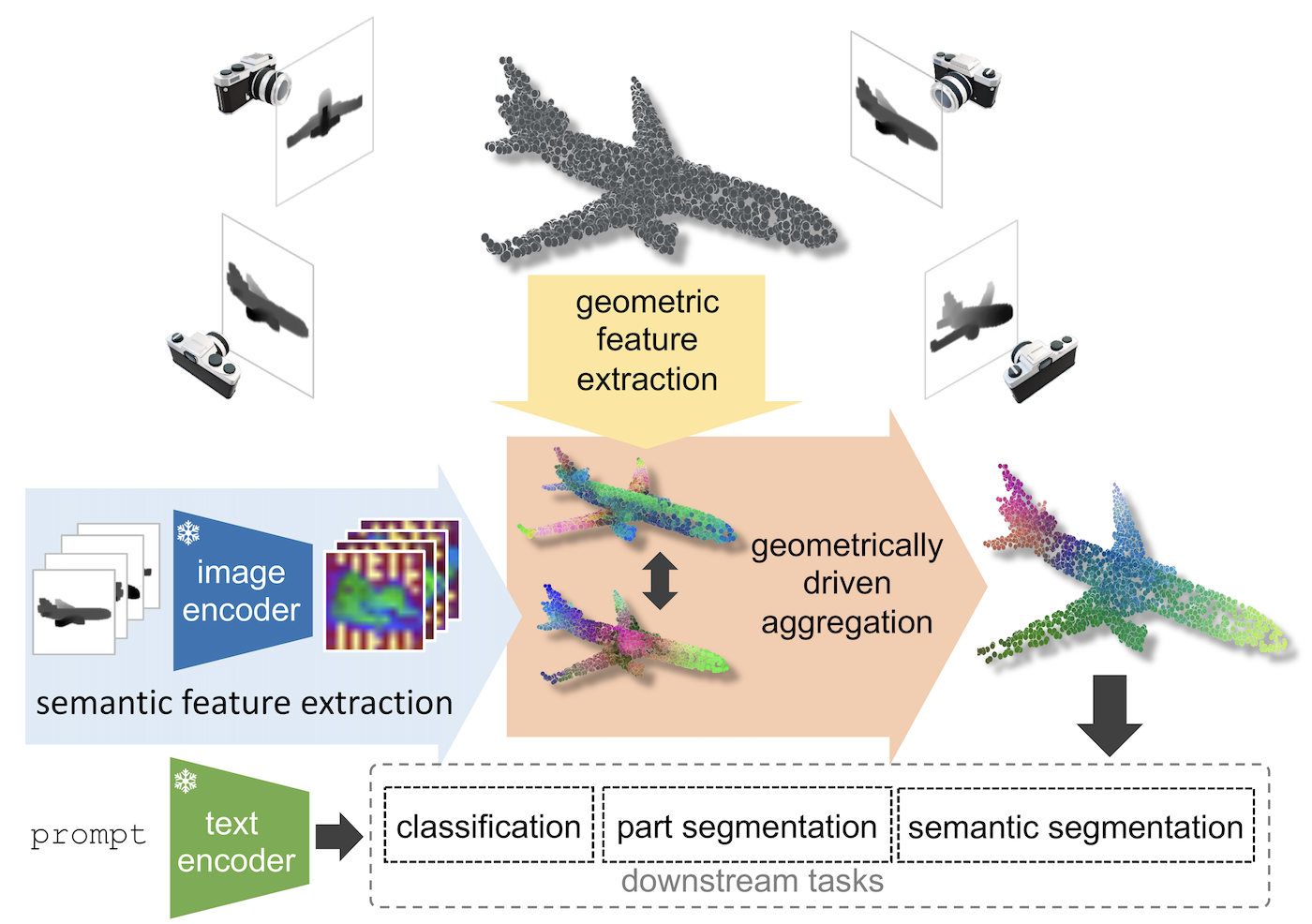 Geometrically-driven Aggregation for Zero-shot 3D Point Cloud UnderstandingGuofeng Mei, Luigi Riz, Yiming Wang, and Fabio PoiesiIn Proceedings of IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), 2024
Geometrically-driven Aggregation for Zero-shot 3D Point Cloud UnderstandingGuofeng Mei, Luigi Riz, Yiming Wang, and Fabio PoiesiIn Proceedings of IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), 2024Zero-shot 3D point cloud understanding can be achieved via 2D Vision-Language Models (VLMs). Existing strategies directly map VLM representations from 2D pixels of rendered or captured views to 3D points, overlooking the inherent and expressible point cloud geometric structure. Geometrically similar or close regions can be exploited for bolstering point cloud understanding as they are likely to share semantic information. To this end, we introduce the first training-free aggregation technique that leverages the point cloud’s 3D geometric structure to improve the quality of the transferred VLM representations. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. We benchmark our approach on three downstream tasks, including classification, part segmentation, and semantic segmentation, with a variety of datasets representing both synthetic/real-world, and indoor/outdoor scenarios. Our approach achieves new state-of-the-art results in all benchmarks.
@inproceedings{mei2024geometrically, title = {Geometrically-driven Aggregation for Zero-shot 3D Point Cloud Understanding}, author = {Mei, Guofeng and Riz, Luigi and Wang, Yiming and Poiesi, Fabio}, booktitle = {Proceedings of IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR)}, year = {2024}, } -
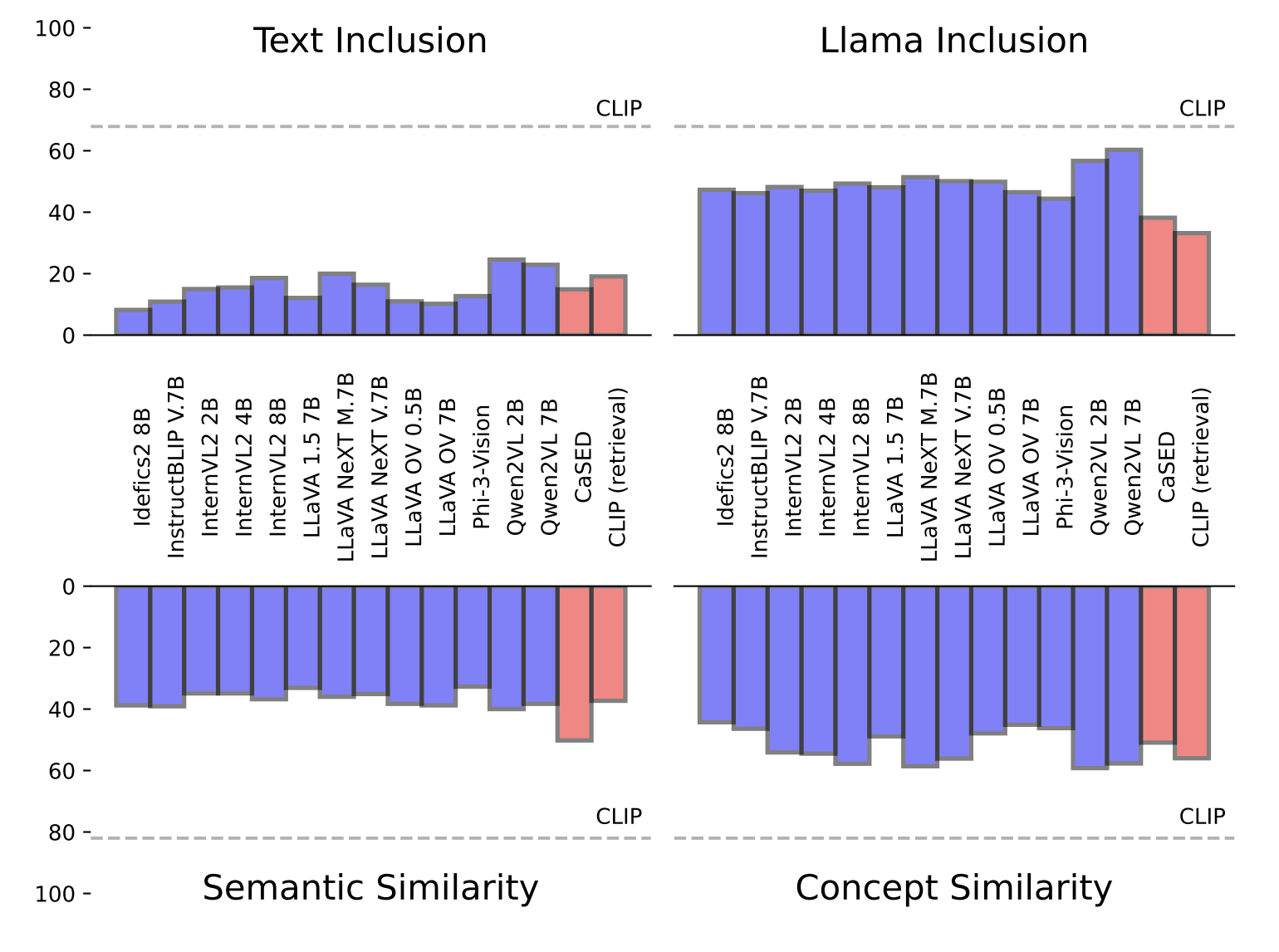
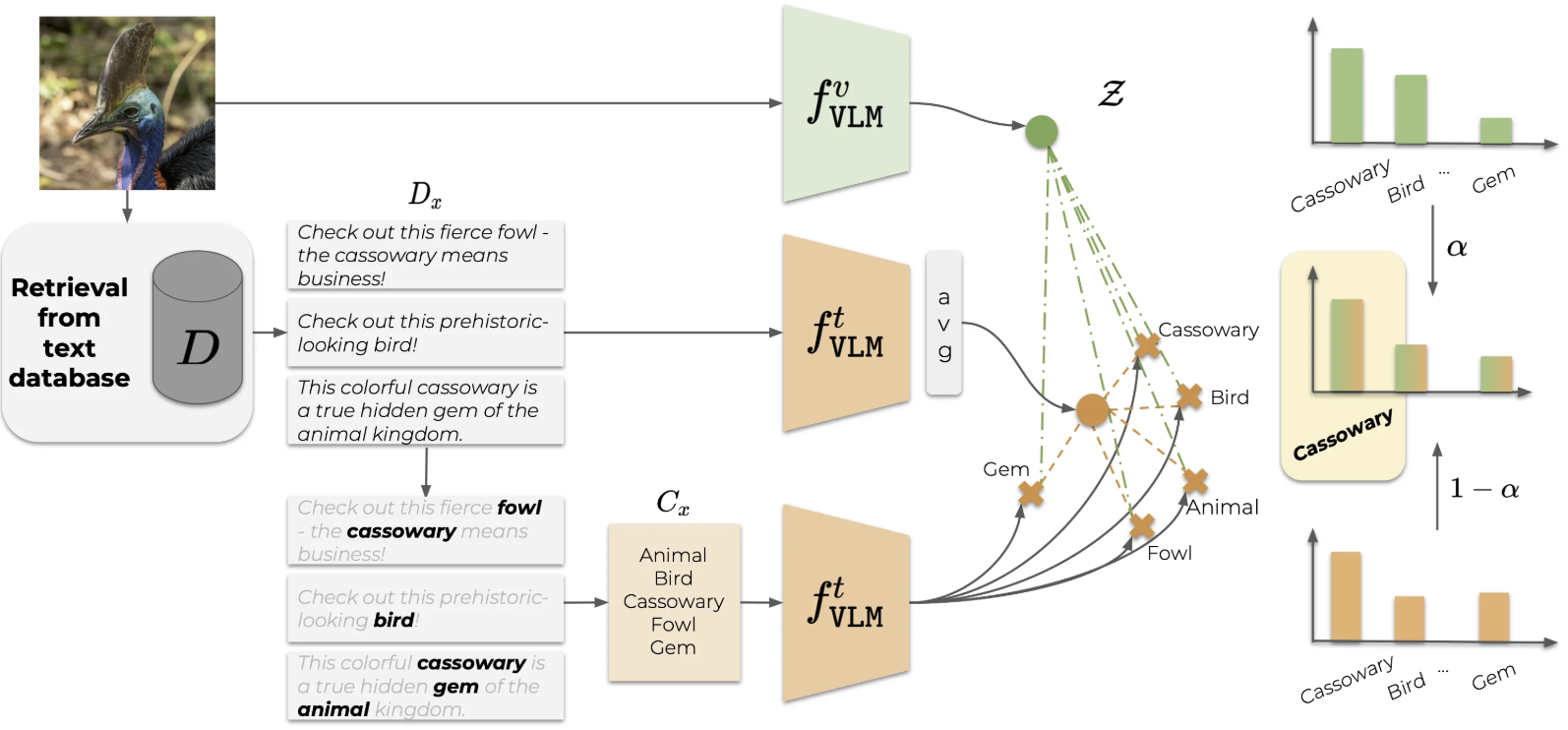 Vocabulary-free Image ClassificationAlessandro Conti, Enrico Fini, Massimiliano Mancini, Paolo Rota, Yiming Wang, and Elisa RicciIn Proceedings of Conference on Neural Information Processing Systems (NeurIPS), 2023
Vocabulary-free Image ClassificationAlessandro Conti, Enrico Fini, Massimiliano Mancini, Paolo Rota, Yiming Wang, and Elisa RicciIn Proceedings of Conference on Neural Information Processing Systems (NeurIPS), 2023Recent advances in large vision-language models have revolutionized the image classification paradigm. Despite showing impressive zero-shot capabilities, a pre-defined set of categories, a.k.a. the vocabulary, is assumed at test time for composing the textual prompts. However, such assumption can be impractical when the semantic context is unknown and evolving. We thus formalize a novel task, termed as Vocabulary-free Image Classification (VIC), where we aim to assign to an input image a class that resides in an unconstrained language-induced semantic space, without the prerequisite of a known vocabulary. VIC is a challenging task as the semantic space is extremely large, containing millions of concepts, with hard-to-discriminate fine-grained categories. In this work, we first empirically verify that representing this semantic space by means of an external vision-language database is the most effective way to obtain semantically relevant content for classifying the image. We then propose Category Search from External Databases (CaSED), a method that exploits a pre-trained vision-language model and an external vision-language database to address VIC in a training-free manner. CaSED first extracts a set of candidate categories from captions retrieved from the database based on their semantic similarity to the image, and then assigns to the image the best matching candidate category according to the same vision-language model. Experiments on benchmark datasets validate that CaSED outperforms other complex vision-language frameworks, while being efficient with much fewer parameters, paving the way for future research in this direction.
@inproceedings{conti2023vocabulary, title = {Vocabulary-free Image Classification}, author = {Conti, Alessandro and Fini, Enrico and Mancini, Massimiliano and Rota, Paolo and Wang, Yiming and Ricci, Elisa}, booktitle = {Proceedings of Conference on Neural Information Processing Systems (NeurIPS)}, year = {2023}, } -
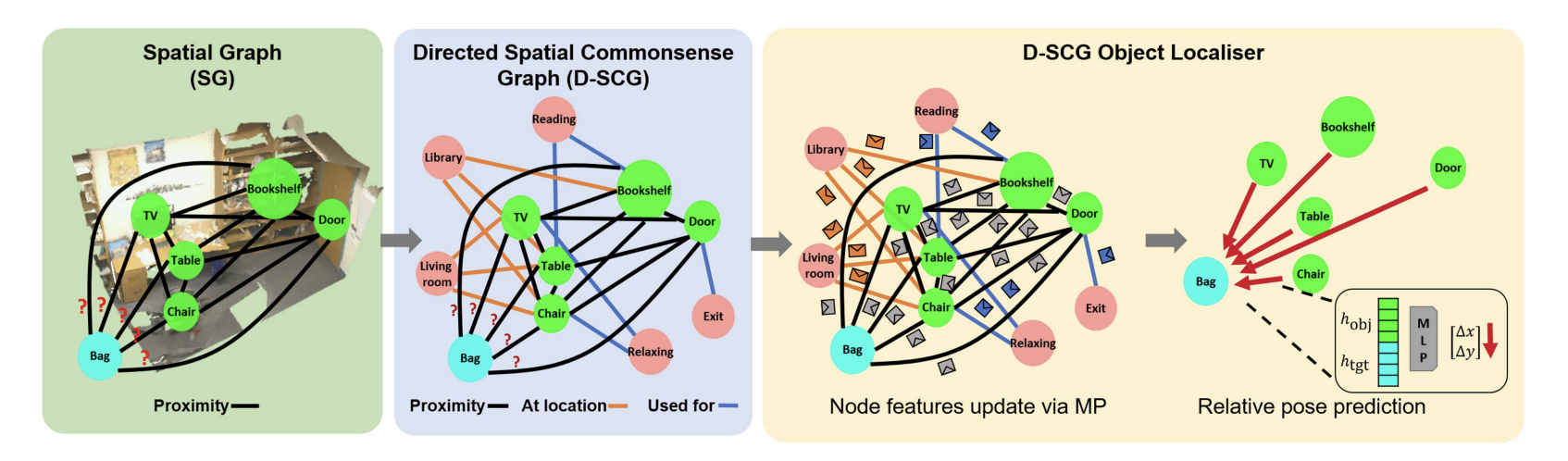 Leveraging commonsense for object localisation in partial scenesFrancesco Giuliari, Geri Skenderi, Marco Cristani, Alessio Del Bue, and Yiming WangIEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023
Leveraging commonsense for object localisation in partial scenesFrancesco Giuliari, Geri Skenderi, Marco Cristani, Alessio Del Bue, and Yiming WangIEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023We propose an end-to-end solution to address the problem of object localisation in partial scenes, where we aim to estimate the position of an object in an unknown area given only a partial 3D scan of the scene. We propose a novel scene representation to facilitate the geometric reasoning, Directed Spatial Commonsense Graph (D-SCG), a spatial scene graph that is enriched with additional concept nodes from a commonsense knowledge base. Specifically, the nodes of D-SCG represent the scene objects and the edges are their relative positions. Each object node is then connected via different commonsense relationships to a set of concept nodes. With the proposed graph-based scene representation, we estimate the unknown position of the target object using a Graph Neural Network that implements a novel attentional message passing mechanism. The network first predicts the relative positions between the target object and each visible object by learning a rich representation of the objects via aggregating both the object nodes and the concept nodes in D-SCG. These relative positions then are merged to obtain the final position. We evaluate our method using Partial ScanNet, improving the state-of-the-art by 5.9% in terms of the localisation accuracy at a 8x faster training speed.
@article{giuliari2023leveraging, title = {Leveraging commonsense for object localisation in partial scenes}, author = {Giuliari, Francesco and Skenderi, Geri and Cristani, Marco and Del Bue, Alessio and Wang, Yiming}, journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)}, year = {2023}, } -
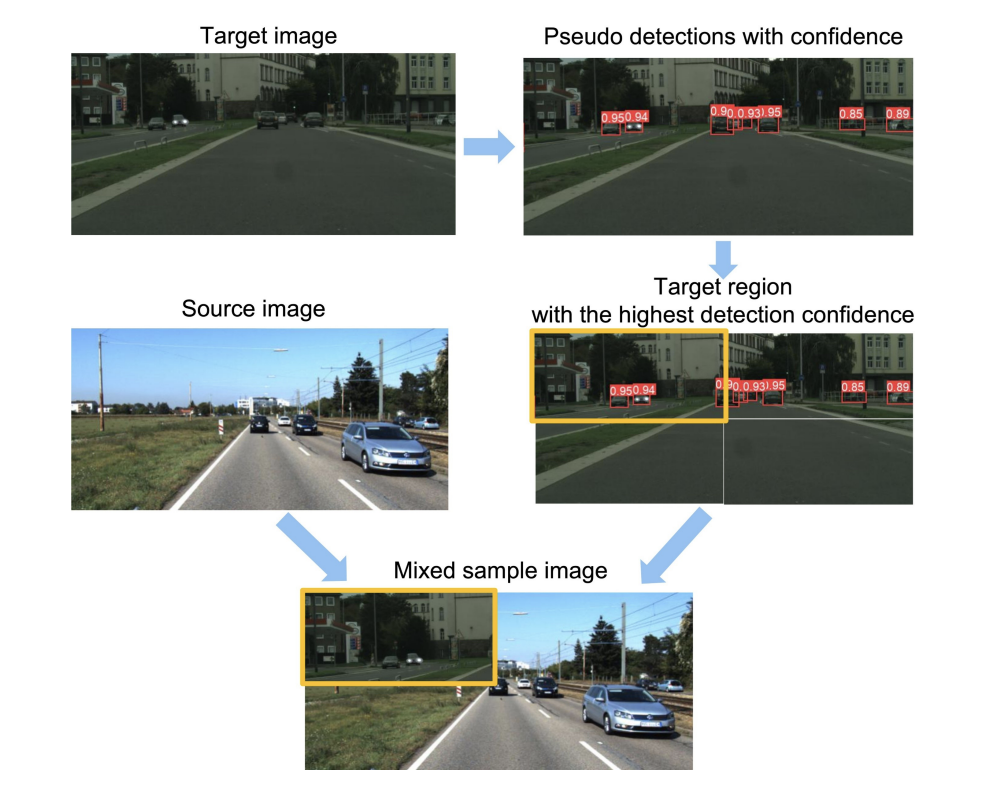 ConfMix: Unsupervised Domain Adaptation for Object Detection via Confidence-based MixingGiulio Mattolin, Luca Zanella, Elisa Ricci, and Yiming WangIn Winter Conference on Applications of Computer Vision (WACV), 2023
ConfMix: Unsupervised Domain Adaptation for Object Detection via Confidence-based MixingGiulio Mattolin, Luca Zanella, Elisa Ricci, and Yiming WangIn Winter Conference on Applications of Computer Vision (WACV), 2023Unsupervised Domain Adaptation (UDA) for object detection aims to adapt a model trained on a source domain to detect instances from a new target domain for which annotations are not available. Different from traditional approaches, we propose ConfMix, the first method that introduces a sample mixing strategy based on region-level detection confidence for adaptive object detector learning. We mix the local region of the target sample that corresponds to the most confident pseudo detections with a source image, and apply an additional consistency loss term to gradually adapt towards the target data distribution. In order to robustly define a confidence score for a region, we exploit the confidence score per pseudo detection that accounts for both the detector-dependent confidence and the bounding box uncertainty. Moreover, we propose a novel pseudo labelling scheme that progressively filters the pseudo target detections using the confidence metric that varies from a loose to strict manner along the training. We perform extensive experiments with three datasets, achieving state-of-the-art performance in two of them and approaching the supervised target model performance in the other.
@inproceedings{mattolin2023confmix, title = {ConfMix: Unsupervised Domain Adaptation for Object Detection via Confidence-based Mixing}, author = {Mattolin, Giulio and Zanella, Luca and Ricci, Elisa and Wang, Yiming}, booktitle = {Winter Conference on Applications of Computer Vision (WACV)}, year = {2023}, } -
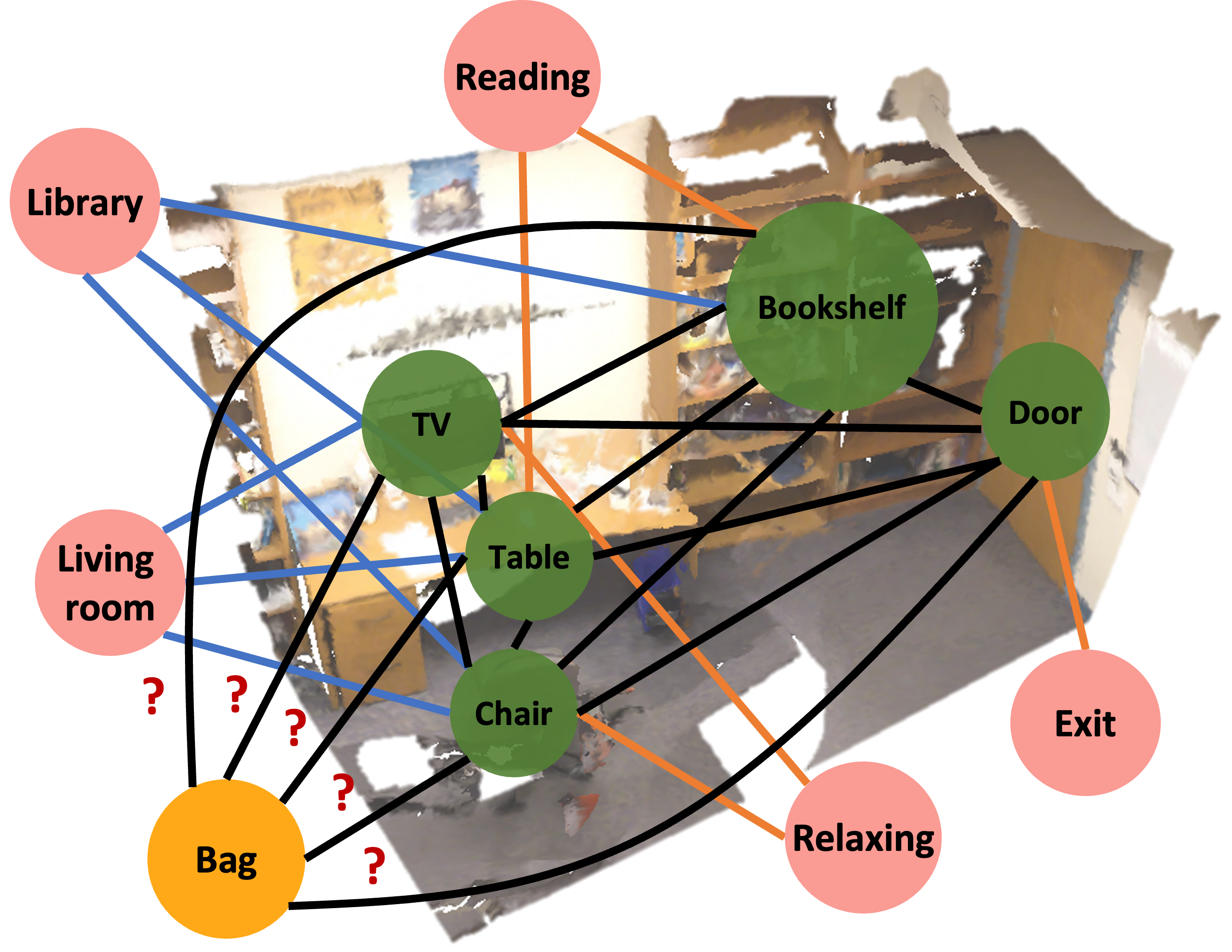 Spatial Commonsense Graph for Object Localisation in Partial ScenesFrancesco Giuliari, Geri Skender, Marco Cristani, Yiming Wang, and Alessio Del BueIn Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Spatial Commonsense Graph for Object Localisation in Partial ScenesFrancesco Giuliari, Geri Skender, Marco Cristani, Yiming Wang, and Alessio Del BueIn Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), 2022We solve object localisation in partial scenes, a new problem of estimating the unknown position of an object (e.g. where is the bag?) given a partial 3D scan of a scene. The proposed solution is based on a novel scene graph model, the Spatial Commonsense Graph (SCG), where objects are the nodes and edges define pairwise distances between them, enriched by concept nodes and relationships from a commonsense knowledge base. This allows SCG to better generalise its spatial inference over unknown 3D scenes. The SCG is used to estimate the unknown position of the target object in two steps: first, we feed the SCG into a novel Proximity Prediction Network, a graph neural network that uses attention to perform distance prediction between the node representing the target object and the nodes representing the observed objects in the SCG; second, we propose a Localisation Module based on circular intersection to estimate the object position using all the predicted pairwise distances in order to be independent of any reference system. We create a new dataset of partially reconstructed scenes to benchmark our method and baselines for object localisation in partial scenes, where our proposed method achieves the best localisation performance.
@inproceedings{giuliari2022spatial, title = {Spatial Commonsense Graph for Object Localisation in Partial Scenes}, author = {Giuliari, Francesco and Skender, Geri and Cristani, Marco and Wang, Yiming and Del Bue, Alessio}, booktitle = {Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2022}, } -
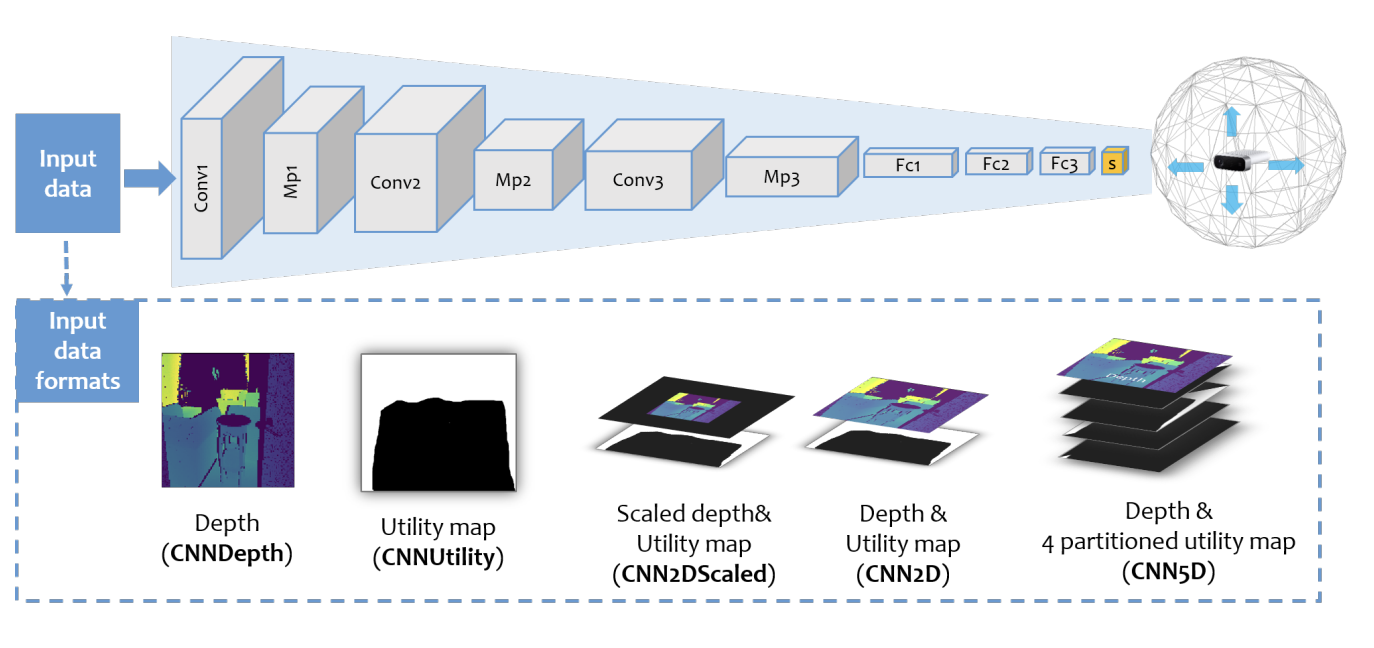 Where to Explore Next? ExHistCNN for History-aware Autonomous 3D ExplorationYiming Wang and Alessio Del BueIn Proceedings of European Conference on Computer Vision (ECCV), 2020
Where to Explore Next? ExHistCNN for History-aware Autonomous 3D ExplorationYiming Wang and Alessio Del BueIn Proceedings of European Conference on Computer Vision (ECCV), 2020In this work we address the problem of autonomous 3D exploration of an unknown indoor environment using a depth camera. We cast the problem as the estimation of the Next Best View (NBV) that maximises the coverage of the unknown area. We do this by re-formulating NBV estimation as a classification problem and we propose a novel learning-based metric that encodes both, the current 3D observation (a depth frame) and the history of the ongoing reconstruction. One of the major contributions of this work is about introducing a new representation for the 3D reconstruction history as an auxiliary utility map which is efficiently coupled with the current depth observation. With both pieces of information, we train a light-weight CNN, named ExHistCNN, that estimates the NBV as a set of directions towards which the depth sensor finds most unexplored areas. We perform extensive evaluation on both synthetic and real room scans demonstrating that the proposed ExHistCNN is able to approach the exploration performance of an oracle using the complete knowledge of the 3D environment.
@inproceedings{wang2020explore, title = {Where to Explore Next? ExHistCNN for History-aware Autonomous 3D Exploration}, author = {Wang, Yiming and Del Bue, Alessio}, booktitle = {Proceedings of European Conference on Computer Vision (ECCV)}, year = {2020}, } -
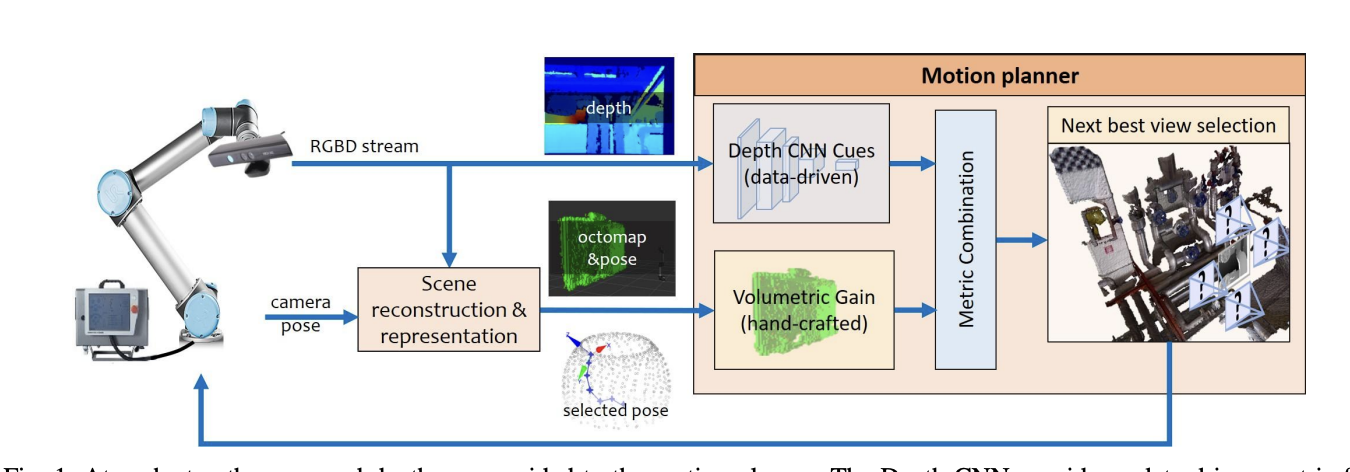 Autonomous 3D reconstruction, mapping and exploration of indoor environments with a robotic armYiming Wang, Stuart James, Elisavet Konstantina Stathopoulou, Carlos Beltrán-González, Yoshinori Konishi, and Alessio Del BueIEEE Robotics and Automation Letters (RA-L), 2019
Autonomous 3D reconstruction, mapping and exploration of indoor environments with a robotic armYiming Wang, Stuart James, Elisavet Konstantina Stathopoulou, Carlos Beltrán-González, Yoshinori Konishi, and Alessio Del BueIEEE Robotics and Automation Letters (RA-L), 2019We propose a novel information gain metric that combines hand-crafted and data-driven metrics to address the next best view problem for autonomous 3-D mapping of unknown indoor environments. For the hand-crafted metric, we propose an entropy-based information gain that accounts for the previous view points to avoid the camera to revisit the same location and to promote the motion toward unexplored or occluded areas. However, for the learnt metric, we adopt a convolutional neural network (CNN) architecture and formulate the problem as a classification problem. The CNN takes the current depth image as input and outputs the motion direction that suggests the largest unexplored surface. We train and test the CNN using a new synthetic dataset based on the SUNCG dataset. The learnt motion direction is then combined with the proposed hand-crafted metric to help handle situations where using only the hand-crafted metric tends to face ambiguities. We finally evaluate the autonomous paths over several real and synthetic indoor scenes including complex industrial and domestic settings and prove that our combined metric is able to further improve the exploration coverage compared to using only the proposed hand-crafted metric.
@article{wang2019autonomous, title = {Autonomous 3D reconstruction, mapping and exploration of indoor environments with a robotic arm}, author = {Wang, Yiming and James, Stuart and Stathopoulou, Elisavet Konstantina and Beltrán-González, Carlos and Konishi, Yoshinori and Del Bue, Alessio}, journal = {IEEE Robotics and Automation Letters (RA-L)}, year = {2019}, } -
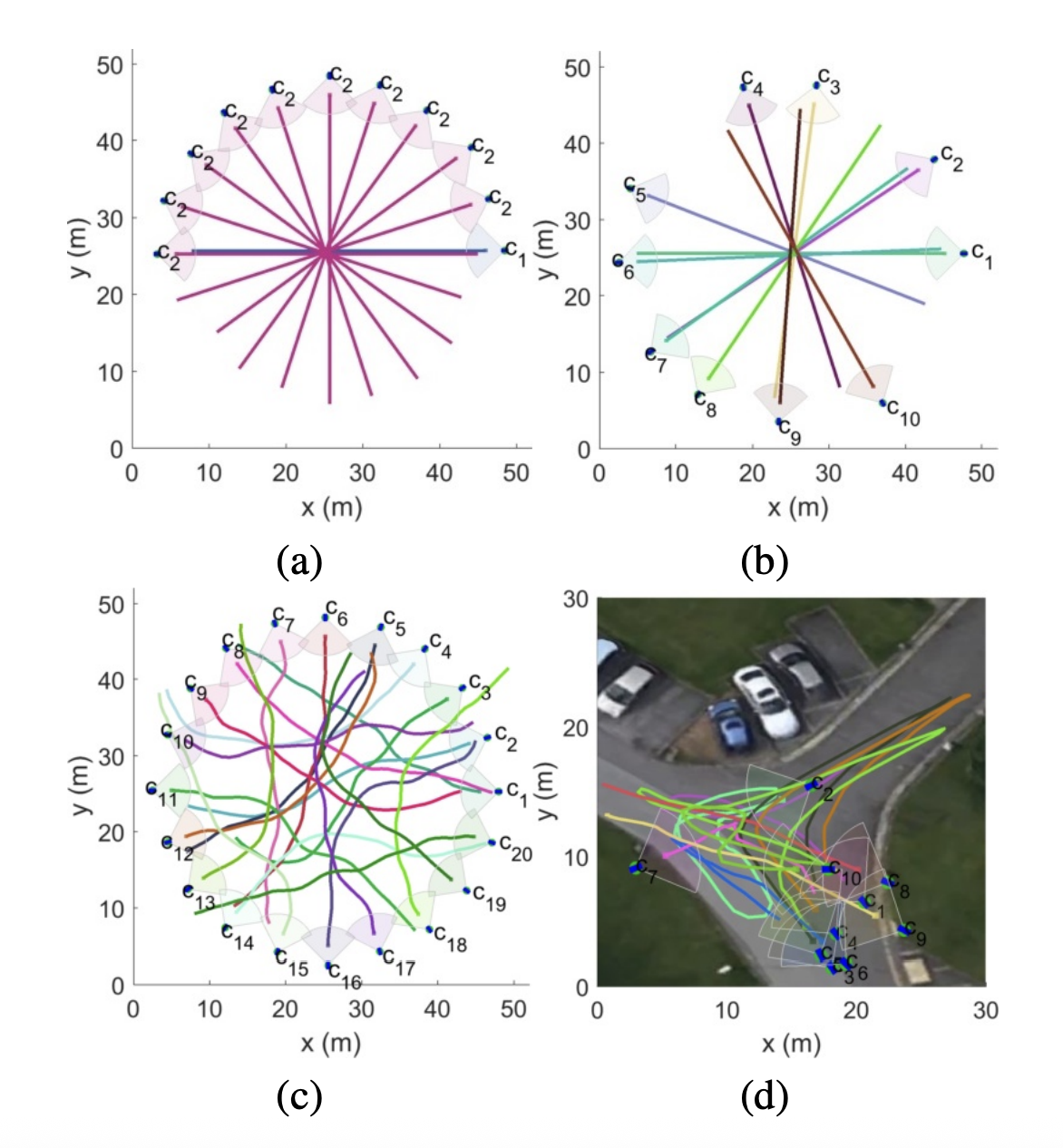 Active visual tracking in multi-agent scenariosYiming Wang and Andrea CavallaroIn Proceedings of IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), 2017
Active visual tracking in multi-agent scenariosYiming Wang and Andrea CavallaroIn Proceedings of IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), 2017We propose an active visual tracker with collision avoidance for camera-equipped robots in dense multi-agent scenarios. The objective of each tracking agent (robot) is to maintain visual fixation on its moving target while updating its velocity to avoid other agents. However, when multiple robots are present or targets intensively intersect each other, robots may have no accessible collision-avoiding paths. We address this problem with an adaptive mechanism that sets the pair-wise responsibilities to increase the total accessible collision-avoiding controls. The final collision-avoiding control accounts for motion smoothness and view performance, i.e. maintaining the target centered in the field of view and at a certain size. We validate the proposed approach under different target-intersecting scenarios and compare it with the Optimal Reciprocal Collision Avoidance and the Reciprocal Velocity Obstacle methods.
@inproceedings{wang2017active, title = {Active visual tracking in multi-agent scenarios}, author = {Wang, Yiming and Cavallaro, Andrea}, booktitle = {Proceedings of IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS)}, pages = {1--6}, year = {2017}, }